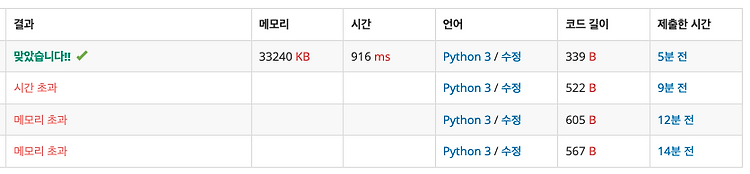
수학적 접근이 필요한 문제였다.
문제에 주어진대로 단순히 브루트포스 탐색할 경우 시간, 메모리 초과가 났다. (아래에 틀린 코드 첨부)
발상
우리가 구할 숫자를 R이라고 해보면
R-x는 M으로 나누어 떨어지고, R-y는 N으로 나누어 떨어진다.
즉 R은 M*p + x 또는 N*q + y이다. (p, q는 자연수)
R의 초기값을 x로 선언하고 R값을 M만큼 증가시키면서 확인해보면 된다.
(y로 선택할 시, 초기값 y, R값을 N만큼 증가시키면서 확인)
정답 코드
최대 범위인 gcd를 구해 while문의 범위를 제한해주었지만,
좀 더 단순하게 M*N으로 해도 이 문제에선 통과할 수 있었다.
import sys
import math
input = sys.stdin.readline
T = int(input())
def cal(M, N, x, y):
R = x # x로 초기화
lcm = abs(M*N) // math.gcd(M, N)
while R <= lcm:
if (R - x) % M == 0 and (R - y) % N == 0:
print(R)
return
R += M
print(-1)
for _ in range(T):
M, N, x, y = list(map(int, input().split()))
cal(M, N, x, y)
틀린 풀이 (메모리 초과)
캘린더 전체를 리스트에 저장하고 리턴하는 코드이다. 당연히 메모리를 많이 잡아먹는다.
import sys
import math
input = sys.stdin.readline
T = int(input())
def cal(M, N, x, y):
lcm = abs(M*N) // math.gcd(M, N)
cal_list = []
cur_x, cur_y = 1, 1
for _ in range(lcm):
cal_list.append((cur_x, cur_y))
if cur_x < M:
cur_x += 1
else:
cur_x = 1
if cur_y < N:
cur_y += 1
else:
cur_y = 1
try:
print(cal_list.index((x, y)) + 1)
except:
print(-1)
for _ in range(T):
M, N, x, y = list(map(int, input().split()))
cal(M, N, x, y)
틀린 풀이 (시간 초과)
리스트에 다 저장하지 않고, 인덱스를 하나씩 증가시키면서 cur_x, cur_y와 비교하는 코드이다.
이전 풀이보다 메모리 사용량은 줄었지만, cur_x, cur_y와 x, y를 여전히 하나씩 비교하고 있다는 점에서 비효율적이다.
import sys
import math
input = sys.stdin.readline
T = int(input())
def cal(M, N, x, y):
lcm = abs(M*N) // math.gcd(M, N)
cur_x, cur_y = 1, 1
for i in range(lcm):
if cur_x == x and cur_y == y:
print(i+1)
return
if cur_x < M:
cur_x += 1
else:
cur_x = 1
if cur_y < N:
cur_y += 1
else:
cur_y = 1
print(-1)
for _ in range(T):
M, N, x, y = list(map(int, input().split()))
cal(M, N, x, y)이 코드의 시간 복잡도를 좀 더 분석해보면, while문 루프에 따라 O(lcm(M, N))이다.
문제 조건에서 두 수 M과 N의 최댓값이 40000이다.
최악의 경우를 생각해보면, M과 N이 서로소인 경우 gcd(M, N)은 1
lcm(M, N) = 40000*40000/1 이라는 1600000000이라는 엄청난 숫자가 나온다.
풀이를 생각할 때 최악의 경우의 시간을 한번 더 생각해보는 습관을 들이자!
ref
https://aia1235.tistory.com/37
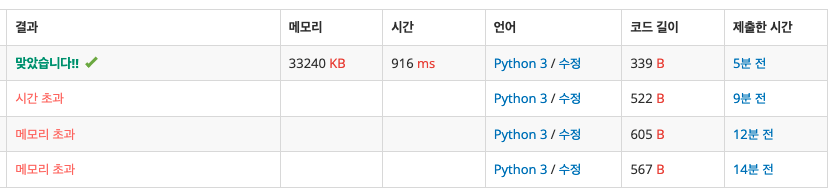
수학적 접근이 필요한 문제였다.
문제에 주어진대로 단순히 브루트포스 탐색할 경우 시간, 메모리 초과가 났다. (아래에 틀린 코드 첨부)
발상
우리가 구할 숫자를 R이라고 해보면
R-x는 M으로 나누어 떨어지고, R-y는 N으로 나누어 떨어진다.
즉 R은 M*p + x 또는 N*q + y이다. (p, q는 자연수)
R의 초기값을 x로 선언하고 R값을 M만큼 증가시키면서 확인해보면 된다.
(y로 선택할 시, 초기값 y, R값을 N만큼 증가시키면서 확인)
정답 코드
최대 범위인 gcd를 구해 while문의 범위를 제한해주었지만,
좀 더 단순하게 M*N으로 해도 이 문제에선 통과할 수 있었다.
import sys
import math
input = sys.stdin.readline
T = int(input())
def cal(M, N, x, y):
R = x # x로 초기화
lcm = abs(M*N) // math.gcd(M, N)
while R <= lcm:
if (R - x) % M == 0 and (R - y) % N == 0:
print(R)
return
R += M
print(-1)
for _ in range(T):
M, N, x, y = list(map(int, input().split()))
cal(M, N, x, y)
틀린 풀이 (메모리 초과)
캘린더 전체를 리스트에 저장하고 리턴하는 코드이다. 당연히 메모리를 많이 잡아먹는다.
import sys
import math
input = sys.stdin.readline
T = int(input())
def cal(M, N, x, y):
lcm = abs(M*N) // math.gcd(M, N)
cal_list = []
cur_x, cur_y = 1, 1
for _ in range(lcm):
cal_list.append((cur_x, cur_y))
if cur_x < M:
cur_x += 1
else:
cur_x = 1
if cur_y < N:
cur_y += 1
else:
cur_y = 1
try:
print(cal_list.index((x, y)) + 1)
except:
print(-1)
for _ in range(T):
M, N, x, y = list(map(int, input().split()))
cal(M, N, x, y)
틀린 풀이 (시간 초과)
리스트에 다 저장하지 않고, 인덱스를 하나씩 증가시키면서 cur_x, cur_y와 비교하는 코드이다.
이전 풀이보다 메모리 사용량은 줄었지만, cur_x, cur_y와 x, y를 여전히 하나씩 비교하고 있다는 점에서 비효율적이다.
import sys
import math
input = sys.stdin.readline
T = int(input())
def cal(M, N, x, y):
lcm = abs(M*N) // math.gcd(M, N)
cur_x, cur_y = 1, 1
for i in range(lcm):
if cur_x == x and cur_y == y:
print(i+1)
return
if cur_x < M:
cur_x += 1
else:
cur_x = 1
if cur_y < N:
cur_y += 1
else:
cur_y = 1
print(-1)
for _ in range(T):
M, N, x, y = list(map(int, input().split()))
cal(M, N, x, y)이 코드의 시간 복잡도를 좀 더 분석해보면, while문 루프에 따라 O(lcm(M, N))이다.
문제 조건에서 두 수 M과 N의 최댓값이 40000이다.
최악의 경우를 생각해보면, M과 N이 서로소인 경우 gcd(M, N)은 1
lcm(M, N) = 40000*40000/1 이라는 1600000000이라는 엄청난 숫자가 나온다.
풀이를 생각할 때 최악의 경우의 시간을 한번 더 생각해보는 습관을 들이자!
ref
https://aia1235.tistory.com/37